Peptide Biomarker Research: A Guide for Researchers

Peptide biomarker research is defined as the systematic identification and validation of short peptide sequences whose abundance or modification state in biological samples correlates with specific disease conditions. The field sits at the intersection of peptidomics, clinical chemistry, and mass spectrometry, and it has matured considerably with the adoption of targeted MS workflows capable of detecting peptides at femtomolar concentrations. Unlike protein biomarkers, peptides are short-lived and highly sensitive to physiological changes, making them responsive to disease states in ways that larger molecules often are not. Recent studies in pancreatic cancer screening and ALS diagnostics have demonstrated that validated peptide panels can achieve diagnostic accuracy that rivals or exceeds established immunoassay methods.
What is peptide biomarker research and how does it work?
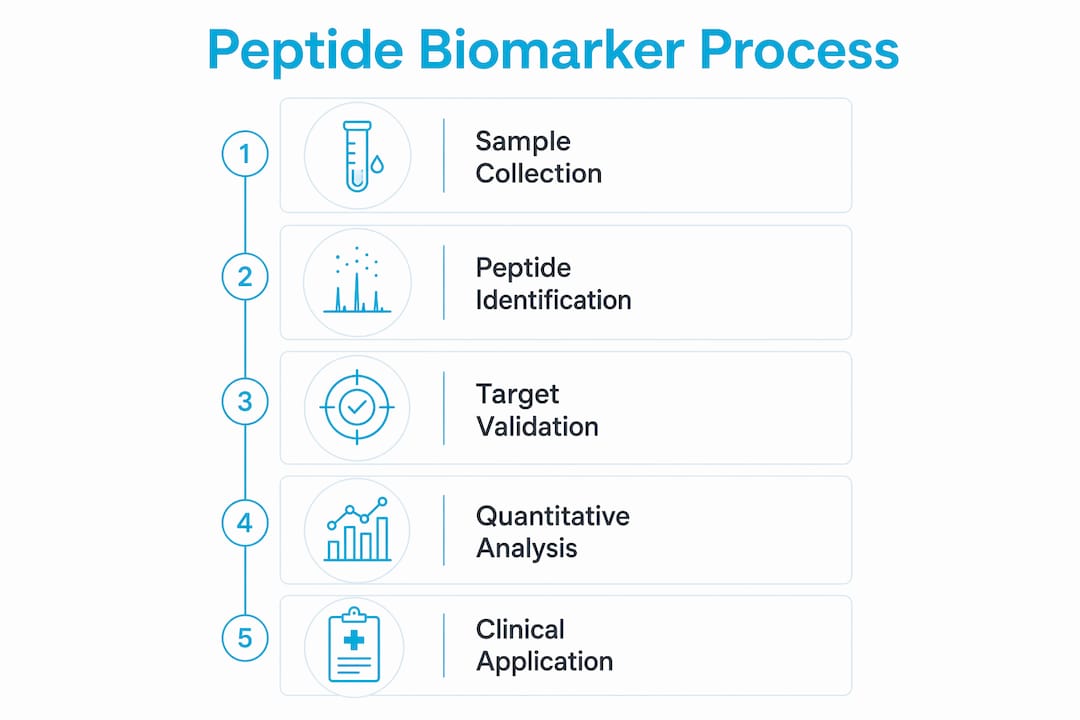
Peptide biomarker research encompasses the full pipeline from biological sample collection through candidate identification, quantitative assay development, and independent cohort validation. The recognized industry term for the analytical discipline underlying this work is peptidomics, which refers to the large-scale study of the peptide complement of a biological system at a given time. Peptidomics divides into two broad workflow categories: untargeted discovery and targeted quantification.
In the discovery phase, data-dependent acquisition (DDA) or data-independent acquisition (DIA) mass spectrometry surveys the full peptide content of a sample without prior hypothesis. This generates candidate lists, often numbering in the thousands. A 2025 peptidomic analysis of cerebrospinal fluid (CSF) from ALS patients identified 33,605 peptides without fractionation, illustrating the analytical depth now achievable with modern instruments. That scale of detection was not feasible a decade ago, and it substantially expands the candidate pool available for downstream validation.

Targeted validation then narrows those candidates using selected reaction monitoring (SRM), multiple reaction monitoring (MRM), or parallel reaction monitoring (PRM). These methods monitor predefined precursor-to-product ion transitions, providing high sensitivity and reproducibility. The tradeoff is that targeted methods require prior assay design, including knowledge of retention times and optimal transition pairs for each peptide. This design phase is frequently the rate-limiting step in translating discovery findings into clinically deployable assays.
Quantitation strategies add another layer of complexity. Label-free approaches rely on peak area comparisons across runs, while label-based methods such as tandem mass tags (TMT) or stable isotope-labeled standards (SIS peptides) provide internal references that correct for run-to-run variation. SIS peptides are the gold standard for absolute quantitation in targeted workflows because they co-elute with the endogenous analyte and share identical ionization behavior.
Pro Tip: When developing a targeted assay, map retention time behavior across at least three instrument configurations before committing to a clinical protocol. Peptide retention times shift with column age, mobile phase lot, and instrument maintenance state. Assays that appear reproducible on a single instrument often fail inter-laboratory reproducibility checks because this variability was not characterized early.
Clinical applications of peptide biomarkers in disease research
Peptide biomarkers have demonstrated clinical utility across oncology, neurology, and immunology, with the strongest evidence currently concentrated in cancer screening and neurodegenerative disease diagnostics.
A 2025 study developed a serum peptide risk index for pancreatic cancer screening that achieved sensitivity of 84% and specificity of 93.4%, with an area under the receiver operating characteristic curve (AUC) of 0.935. Performance was validated in an independent cohort, which is a non-negotiable requirement for any biomarker claim to carry clinical weight. Pancreatic cancer is notoriously difficult to detect at early stages using conventional imaging or CA 19-9 serology, so a serum peptide panel with this performance profile represents a meaningful advance.
In neurology, MS-based peptidomic analysis of CSF identified an eight-peptide ALS panel with a diagnostic AUC of 98%, outperforming single neurofilament light (NfL) peptide assays. The panel’s superiority over NfL alone reflects a core principle in biomarker research: disease biology affects multiple molecular pathways simultaneously, and panels capture that complexity more accurately than single markers. The ALS study also confirmed correlation with established immunoassay results, providing cross-platform validation that strengthens confidence in the MS-derived measurements.
Immuno-oncology represents a third growth area. HLA-bound peptides, also called the immunopeptidome, are presented on tumor cell surfaces and can serve as targets for neoantigen-based therapies or as biomarkers of immune activation. Identifying these peptides requires specialized immunopeptidomics workflows distinct from standard serum or CSF peptidomics, including immunoaffinity enrichment of HLA complexes prior to MS analysis.
Key disease areas where peptide biomarkers currently show validated or emerging diagnostic value include:
Pancreatic cancer: serum peptide risk index models with high AUC performance
Amyotrophic lateral sclerosis: CSF peptide panels outperforming single-protein assays
Colorectal cancer: fecal and plasma peptide candidates under active investigation
Cardiovascular disease: natriuretic peptide fragments as established clinical markers
Alzheimer’s disease: amyloid-derived peptide fragments in CSF and plasma
Challenges and recent advances in peptide biomarker research
The primary technical challenge in peptide biomarker research is identification confidence. Stochastic sampling in DDA acquisition means that low-abundance peptides may be detected in some runs and missed in others, introducing false negatives that distort candidate lists. Spectral library quality compounds this problem: peptides not represented in a reference library cannot be confidently identified, regardless of instrument sensitivity.
User-defined peptide spectral libraries address this directly. A 2025 study in immunopeptidomics demonstrated that custom spectral libraries recovered more than 75% of expected peptide sequences and enabled detection of peptides at 0.1 femtomole concentrations in complex biological backgrounds. That level of sensitivity is critical for low-abundance disease-associated peptides that would otherwise fall below detection thresholds using generic library-based searches. The practical implication is that teams investing in library construction for their specific sample type and disease context gain a substantial analytical advantage.
A second challenge is biological variability. Peptide abundance in serum, CSF, or tissue reflects not only disease state but also sample handling time, freeze-thaw cycles, protease activity during collection, and patient-level factors such as age, sex, and comorbidities. Biomarker candidates that perform well in a discovery cohort frequently fail in independent validation because these confounders were not controlled. The multi-phase pipeline described in recent Nature Communications work explicitly separates discovery, candidate selection, linear-response testing, and final validation to reduce this attrition.
The table below compares single-peptide and multi-peptide panel approaches across the dimensions most relevant to clinical translation:
Criterion Single-peptide marker Multi-peptide panel Diagnostic AUC Typically 0.70 to 0.85 Typically 0.90 to 0.98 Biological robustness Sensitive to single-pathway variation Captures multi-pathway disease biology Assay complexity Lower; one transition set Higher; requires multiplexed MRM or PRM Regulatory path Simpler analytical validation Requires panel-level co-validation Failure mode Single false negative invalidates result Redundancy reduces false negative rate
Pro Tip: Before committing to a biomarker candidate from a discovery dataset, test it against at least two publicly available independent cohorts using the same quantitative method. Candidates that survive this cross-cohort screen have a substantially higher probability of holding up in prospective clinical validation.
Analytical tools and techniques supporting biomarker investigations
Mass spectrometry is the central technology in peptidomics, but the specific acquisition mode determines what information is captured and how it can be used downstream. DDA selects the most abundant precursor ions for fragmentation in each cycle, providing rich spectral data but missing low-abundance species. DIA fragments all precursors within defined mass windows simultaneously, producing more complete coverage at the cost of more complex spectra that require sophisticated deconvolution software such as Spectronaut or DIA-NN.
Quantitative proteomics techniques relevant to peptide biomarker work include:
Label-free quantitation (LFQ): compares peptide peak areas across runs; lower cost but higher coefficient of variation
Tandem mass tags (TMT): isobaric labeling enabling multiplexed comparison of up to 18 samples per run
Stable isotope-labeled standards (SIS): synthetic heavy-isotope peptides used as internal standards for absolute quantitation in targeted assays
Data-independent acquisition (DIA): provides reproducible peptide quantitation across large sample cohorts without the stochastic sampling limitations of DDA
Phage display: used to identify peptide sequences with high affinity for disease-associated targets, complementing MS-based discovery
Statistical modeling is as important as the analytical platform. Logistic regression applied to peptide abundance data generates risk scores, as demonstrated in the pancreatic cancer serum peptide study. AUC, sensitivity, and specificity are the standard performance metrics, but calibration curves and decision curve analysis are increasingly required by reviewers to demonstrate clinical utility beyond discrimination alone.
Bioinformatics pipelines such as MaxQuant, Proteome Discoverer, and FragPipe handle raw spectral data processing, while downstream statistical analysis typically occurs in R or Python environments. Reproducibility across these pipelines is not guaranteed: the same raw data processed through different software versions can yield different peptide identification lists, a source of irreproducibility that the field is actively working to standardize.
The role of nanoparticle technologies is also expanding. Nanoparticles functionalized with peptide-binding ligands can pre-enrich low-abundance biomarker candidates from plasma before MS analysis, effectively extending the dynamic range of detection without requiring additional instrument sensitivity.
Key takeaways
Peptide biomarker research delivers its highest diagnostic value through validated multi-peptide panels analyzed by targeted mass spectrometry in independent patient cohorts.
Point Details Definition of the field Peptidomics identifies short peptides correlated with disease states for diagnosis, prognosis, or treatment monitoring. Discovery vs. targeted workflows DDA/DIA discovery generates candidates; SRM/MRM/PRM targeted methods provide the quantitative precision needed for clinical assays. Panel superiority Multi-peptide panels consistently achieve higher AUC than single markers, as shown in ALS CSF (AUC 98%) and pancreatic cancer studies. Validation requirement Independent cohort validation with sensitivity, specificity, and AUC metrics is non-negotiable for any clinically credible biomarker claim. Library construction advantage Custom spectral libraries recover more than 75% of expected sequences and enable femtomolar-level detection in complex samples.
Why single-marker thinking still dominates, and why it shouldn’t
The field has known for years that multi-peptide panels outperform single markers, yet most early-stage biomarker studies still report a single candidate peptide as the headline finding. This happens for practical reasons: panels require more complex assay development, larger sample sizes for statistical power, and more expensive multiplexed reagents. Single-marker studies are faster to publish and easier to fund at the exploratory stage.
The problem is that this creates a literature full of promising single-peptide candidates that fail when tested in broader populations. The ALS CSF panel achieving 98% AUC is not an anomaly. It reflects what happens when researchers commit to the harder work of panel construction and independent validation rather than stopping at discovery. The pancreatic cancer serum peptide risk index followed the same logic: a composite score derived from multiple peptides, validated in a separate cohort, with performance metrics that would be impossible to achieve with any single analyte.
From a practical standpoint, researchers entering this field should treat the multi-phase pipeline described in recent Nature Communications work as a minimum standard, not an aspirational one. The phases exist to prevent the most common failure modes: overfitting to a discovery cohort, selecting candidates that lack linear quantitative response, and reporting AUC values that do not replicate. Skipping phases does not accelerate translation. It produces results that cannot be reproduced, which ultimately costs more time than following the full pipeline from the start.
The technological trajectory is favorable. DIA acquisition, improved spectral libraries, and software advances are reducing the cost and complexity of generating reproducible peptide quantitation data across large cohorts. The bottleneck is shifting from analytical sensitivity to study design and validation rigor.
— Sam Levin
Research-grade peptides for biomarker investigations
Peptide biomarker research depends on reference standards and study compounds that meet consistent purity and batch specifications. PeptidesFromChina supplies research-grade peptides with independent purity verification and batch traceability documentation, supporting the reproducibility requirements that rigorous biomarker studies demand. The platform’s peptide quality verification process covers raw API sourcing, lyophilization consistency, and third-party analytical confirmation, which are the factors that determine whether a peptide reference standard performs reliably across multiple experimental runs. Researchers sourcing compounds for biomarker validation work can review the full research peptide catalog for available compounds, including signaling peptides and neuropeptides relevant to current biomarker investigations.
FAQ
What is the difference between peptidomics and proteomics?
Peptidomics focuses specifically on endogenous peptides present in biological samples, while proteomics studies the full protein complement. Peptides analyzed in peptidomics are typically shorter, more labile, and more directly reflective of real-time physiological changes than intact proteins.
Why are peptide panels more accurate than single-peptide biomarkers?
Disease processes affect multiple molecular pathways simultaneously, so panels capture that biological complexity more completely than any single analyte. The ALS CSF peptide panel achieved a diagnostic AUC of 98%, substantially outperforming single neurofilament light peptide assays.
What mass spectrometry methods are used in peptide biomarker validation?
SRM, MRM, and PRM are the primary targeted MS methods used in validation workflows. These approaches monitor specific precursor-to-product ion transitions, providing the sensitivity and reproducibility required for quantitative clinical assays.
How important is independent cohort validation for peptide biomarkers?
Independent cohort validation is the defining requirement for any clinically credible biomarker. Candidates that perform well in discovery cohorts frequently fail in separate populations due to biological variability and overfitting, making external validation a mandatory step before clinical claims can be made.
What role do spectral libraries play in peptide identification?
Spectral libraries provide reference fragmentation patterns against which experimental spectra are matched. Custom user-defined libraries recover more than 75% of expected peptide sequences and enable detection at 0.1 femtomole concentrations, substantially improving identification confidence over generic library searches.